

What is data quality?
Data quality is the degree to which information meets an organization’s standards for accuracy, validity, completeness, consistency, uniqueness, and timeliness.
High-quality data enables confident, informed choices. When data quality fails, it undermines customer service, productivity, governance, and strategy. Even a single error can ripple across systems, disrupting reports, analytics, and planning. Poor quality also erodes credibility, damages stakeholder trust, and can create regulatory, reputational, or financial risks.
Maintaining data quality is essential for both trust and efficiency. By continuously monitoring and addressing issues, organizations can ensure that data remains fit for its intended purpose and delivers value across the business. In this way, it is a critical aspect of data management, ensuring that the data used for analysis, reporting, and decision-making is reliable and trustworthy.
Why is data quality important?
Data quality is important because it directly impacts the accuracy and reliability of information used for decision-making. Quality data is key to making accurate, informed decisions. While all data has some level of “quality,” a variety of characteristics and factors determines the degree of data quality (high-quality versus low-quality).

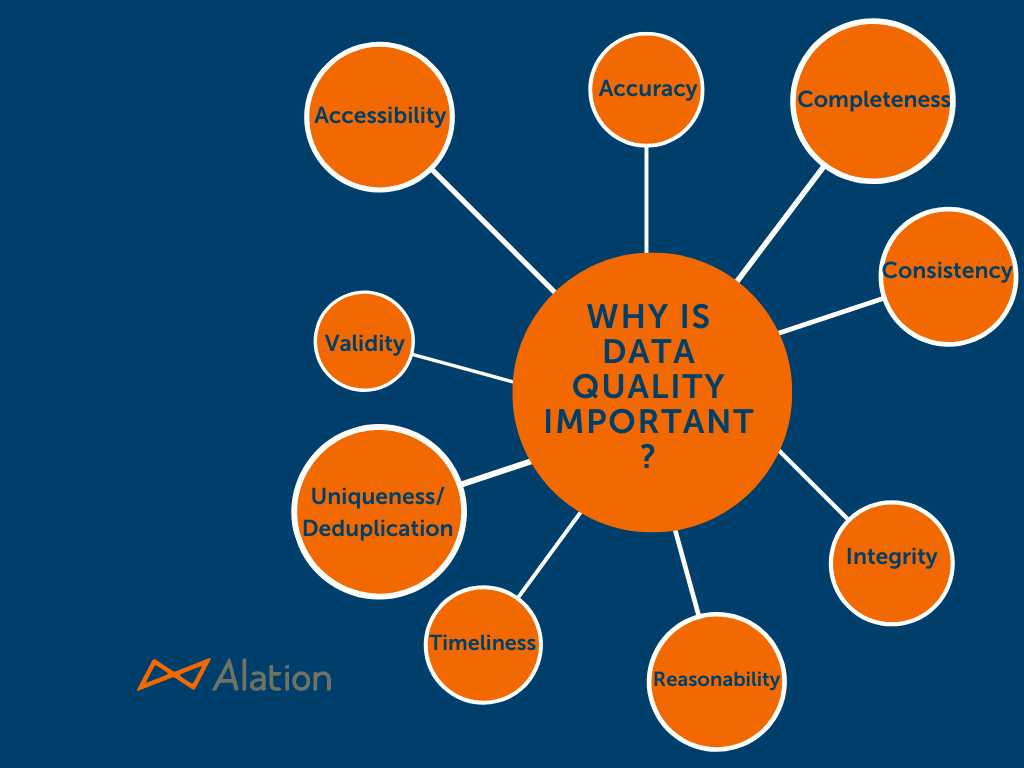
9 popular data quality characteristics and dimensions
Different data quality characteristics will likely be more important to various stakeholders across the organization. A list of popular data quality characteristics and dimensions include:
Accuracy
Completeness
Consistency
Integrity
Reasonability
Timeliness
Uniqueness/Deduplication
Validity
Accessibility
What is good data quality?
Data accuracy is a key attribute of high-quality data, a single inaccurate data point can wreak havoc across the entire system.
Without accuracy and reliability in data quality, executives cannot trust the data or make informed decisions. This can, in turn, increase operational costs and wreak havoc for downstream users. Analysts wind up relying on imperfect reports and making misguided conclusions based on those findings. And the productivity of end-users will diminish due to flawed guidelines and practices being in place.
Poorly maintained data can lead to a variety of other problems, too. For example, out-of-date customer information may result in missed opportunities for up- or cross-selling products and services.
Low-quality data might also cause a company to ship their products to the wrong addresses, resulting in lowered customer satisfaction ratings, decreases in repeat sales, and higher costs due to reshipments.
And in more highly regulated industries, bad data can result in the company receiving fines for improper financial or regulatory compliance reporting.
Top 3 data quality challenges
Data volume presents quality challenges. Whenever large amounts of data are at play, the sheer volume of new information often becomes an essential consideration in determining whether the data is trustworthy. For this reason, forward-thinking companies have robust processes in place for the collection, storage, and processing of data.
As the technological revolution advances at a rapid pace, the top three data quality challenges include:
1. Privacy and protection laws
The General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), which gives people the right to access their personal data, are substantially increasing public demand for accurate customer records. Organizations must be able to locate the totality of an individual’s information almost instantly and without missing even a fraction of the collected data because of inaccurate or inconsistent data.
2. Artificial Intelligence (AI) and Machine Learning (ML)
As more companies implement Artificial Intelligence and Machine Learning applications to their business intelligence strategies, data users may find it increasingly difficult to keep up with new surges of Big Data. Because these real-time data streaming platforms channel vast quantities of new information continuously, there are now even more opportunities for mistakes and data quality inaccuracies.
Furthermore, larger corporations must work diligently to manage their systems, which reside both on-premises and through cloud servers. The abundance of data systems has also made the monitoring of complicated tasks even more challenging.
3. Data governance practices
Data governance is a data management system that adheres to an internal set of standards and policies for the collection, storage, and sharing of information. By ensuring that all data is consistent, trustworthy, and free from misuse within every company department, managers can guarantee compliance with important regulations and reduce the risk of the business being fined.
Without the right data governance approach, the company may never resolve inconsistencies within different systems across the organization. For example, customer names can be listed differently depending on the department. Sales might say “Sally.” Logistics uses “Sallie.” And customer service lists the name as “Susan.” This poor-quality data governance can result in confusion for customers that have multiple interactions with each department over time.
Emerging data quality challenges
As data changes, organizations face new data quality issues that need quick solutions. Consider these additional challenges:
Data quality in data lakes
When data lakes store a variety of data types, maintaining data quality is doubly challenging. Organizations need effective strategies to ensure data in data lakes remains accurate, up-to-date, and accessible.
Dark data
Dark data describes data that organizations collect but do not use or analyze. It can present a big problem. Uncovering valuable insights from dark data while maintaining its quality is a growing concern.
Edge computing
The rise of edge computing, where data is processed closer to its source, introduces challenges in ensuring data quality at the edge. Organizations must address issues related to data consistency, latency, and reliability in edge environments.
Data quality ethics
Ethical considerations in data quality are gaining importance. To safeguard data quality, leaders must address bias, fairness, and transparency questions as they relate to data collection and usage, particularly in AI and ML applications.
Data Quality as a Service (DQaaS)
The emergence of DQaaS solutions offers opportunities and challenges. Organizations must evaluate the effectiveness and reliability of third-party data quality services while integrating them into their data ecosystems.
Data quality in multi-cloud environments
Managing data quality across multiple cloud platforms and environments requires specialized expertise. Inconsistent data formats, accessibility issues, and integration complexities must be addressed.
Data quality culture
Fostering a data quality culture across the organization is an ongoing challenge. Educating employees about the importance of data quality and encouraging data stewardship is crucial for long-term success.
By addressing these new data quality problems, organizations can keep their data reliable and accurate, enabling data-driven decision-making, ensuring compliance with evolving regulations, and leveraging data as a strategic asset.
Benefits of good data quality
High data quality has multiple advantages. It saves money by reducing the expenses of fixing bad data and prevents costly errors and disruptions. It also improves the accuracy of analytics, leading to better business decisions that boost sales, streamline operations, and deliver a competitive edge.
Finally, high data quality builds trust in analytics tools and BI dashboards. Reliable data encourages business users to use these tools for decision-making instead of relying on gut feelings or makeshift spreadsheets. Efficient data quality management also allows data teams to focus on more valuable tasks, like helping users and analysts use data for strategic insights and promoting data quality best practices to reduce errors in daily operations.
How to measure data quality: 6 standards & dimensions
The Data Quality Assessment Framework (DQAF) is a set of data quality dimensions, organized into six major categories: completeness, timeliness, validity, integrity, uniqueness, and consistency.

These dimensions are useful when evaluating the quality of a particular dataset at any point in time. Most data managers assign a score of 0-100 for each dimension, an average DQAF.
1. Completeness
Completeness is defined as a measure of the percentage of data that is missing within a dataset. For products or services, the completeness of data is crucial in helping potential customers compare, contrast, and choose between different sales items. For instance, if a product description does not include an estimated delivery date (when all the other product descriptions do), then that “data” is incomplete.
2. Timeliness
Timeliness measures how up-to-date or antiquated the data is at any given moment. For example, if you have information on your customers from 2008, and it is now 2021, then there would be an issue with the timeliness as well as the completeness of the data.
When determining data quality, the timeliness dimension can have a tremendous effect — either positive or negative — on its overall accuracy, viability, and reliability.
3. Validity
Validity refers to information that fails to follow specific company formats, rules, or processes. For example, many systems may ask for a customer’s birthdate. However, if the customer does not enter their birthdate using the proper format, the level of data quality becomes automatically compromised. Therefore, many organizations today design their systems to reject birthdate information unless it is input using the pre-assigned format.
4. Integrity
Integrity of data refers to the level at which the information is reliable and trustworthy. Is the data true and factual? For example, if your database has an email address assigned to a specific customer, and it turns out that the customer actually deleted that account years ago, then there would be an issue with data integrity as well as timeliness.
5. Uniqueness
Uniqueness is a data quality characteristic most often associated with customer profiles. A single record can be all that separates your company from winning an e-commerce sale and beating the competition.
Greater accuracy in compiling unique customer information, including each customer’s associated performance analytics related to individual company products and marketing campaigns, is often the cornerstone of long-term profitability and success.
6. Consistency
Consistency of data is most often associated with analytics. It ensures that the source of the information collection is capturing the correct data based on the unique objectives of the department or company.
For example, let’s say you have two similar pieces of information:
the date on file for the opening of a customer’s account vs.
the last time they logged into their account.
The difference in these dates may provide valuable insights into the success rates of current or future marketing campaigns.
Determining the overall quality of company data is a never-ending process. The most crucial components of effective data quality management are the identification and resolution of potential issues quickly and proactively.

Understanding data quality intersections
When assessing data quality, it's important to consider how different aspects of quality can affect each other. For example, the completeness of data can impact its timeliness. Incomplete data may fail to capture the full picture of events, impacting time to insight. Also, the accuracy of data can be linked to its reliability, especially if it doesn't follow certain rules. Thus, it's crucial to consider these connections for a thorough understanding of data quality and to make sure the data is accurate, reliable, and useful for decision-making.
Data quality management tools & best practices
Data is generated by people, who are inherently prone to human error. To avoid future problems and maintain data quality continuity, your organization can adopt certain best practices that will ensure the integrity of your data quality management system for years into the future. Such measures include:
Establish employee and interdepartmental buy-in across the enterprise.
Set clearly defined metrics.
Ensure high data quality with data governance by establishing guidelines that oversee every aspect of data management.
Create a process where employees can report any suspected failures regarding data entry or access.
Establish a step-by-step process for investigating negative reports.
Launch a data auditing process.
Establish and invest in a high-quality employee training program.
Establish, maintain, and consistently update data security standards.
Assign a data steward at each level throughout your company.
Leverage potential cloud data automation opportunities.
Integrate and automate data streams wherever possible.
Data quality vs. data integrity
Data quality and data integrity are closely related concepts in data management, and are often used interchangeably. Data quality ensures the overall accuracy, completeness, consistency, and timeliness of data, making it fit for its intended use. On the other hand, data integrity is a broader concept that encompasses data accuracy and security as a whole.
Data integrity has two sides: logical and physical. Logically, it ensures that related data in different tables stay correct and connected. Physically, it uses controls and security to stop unauthorized changes or damage to data. It also includes backups to keep data safe and recoverable in case of unforeseen events. While data quality makes data useful, data integrity keeps it safe and reliable in a system or database.
Data quality with Alation
Recently, Alation CEO Satyen Sagani spoke about the importance of trusted data and how Alation's Data Intelligence Platform helps organizations manage their data on Bloomberg Technology. Listen below to check out the insights.
Alation provides a variety of enterprise-level tools and solutions for the implementation of cost-effective data quality management systems. We help organizations consolidate siloed and distributed enterprise data, build consistency in data practices, and improve both the speed and the quality of the decision-making process. For more information, check out Alation's Data Quality Solution today!

- What is data quality?
- Why is data quality important?
- 9 popular data quality characteristics and dimensions
- What is good data quality?
- Top 3 data quality challenges
- Emerging data quality challenges
- Benefits of good data quality
- How to measure data quality: 6 standards & dimensions
- Data quality management tools & best practices
- Data quality vs. data integrity
- Data quality with Alation
Contents
FAQs
What is data quality?
Data quality is defined as the degree to which data meets a company’s expectations of accuracy, validity, completeness, and consistency. It is a critical aspect of data management, ensuring that the data used for analysis, reporting, and decision-making is reliable and trustworthy.
Why Is data quality important?
Data quality is important because it directly impacts the accuracy and reliability of information used for decision-making. Quality data is key to making accurate, informed decisions. While all data has some level of “quality,” a variety of characteristics and factors determines the degree of data quality (high-quality versus low-quality).
How do you measure the ROI of data quality systems?
ROI of data quality systems is measured through reduced errors, improved decision-making, streamlined operations, and increased revenue from better-targeted strategies, quantifying savings and additional income against implementation costs.
What are common challenges in fostering a data quality culture?
Common challenges include resistance to change, lack of awareness, and inconsistent practices. Addressing these requires leadership buy-in, ongoing education, clear communication, and incentivizing adherence to data quality standards.
How does Alation address emerging data quality challenges?
Alation's platform ensures data quality in lakes by maintaining accuracy and accessibility. It addresses edge computing challenges by ensuring data consistency and integrity at the source. It also promotes ethical data practices, fostering transparency and fairness in data usage.
Tagged with
Loading...